
Von Bäumen, Netzen und Maschinen
Drei KlassifizierungsverfahrenIn einem vergangenen Post habe ich bereits über künstliche Intelligenz und maschinelles Lernen im Allgemeinen gesprochen. In diesem Artikel möchte ich nun drei ganz konkrete Verfahren des maschinellen Lernens vorstellen, genauer gesagt drei Klassifizierungsverfahren.
Klassifizierung ist ein Teilbereich des überwachten Lernens, bei dem aus einer Reihe von Eingabe-Ausgabe-Paaren eine Regel abgeleitet werden soll, die Eingabe auf Ausgabe abbildet.1 Diese Lernaufgabe wird im maschinellen Lernen auch „Funktionenlernen aus Beispielen“ genannt,2 die gelernten Regeln häufig „Modelle“. Bei den Eingabedaten spricht man auch von „feature variables“ oder einem Merkmalsvektor, bei den Ausgabedaten von „target variables“,3 die im Falle von Klassifizierung aus einer endlichen Wertemenge aus zuzuordnenden „Klassen“ oder „Labels“ stammen.1
Klassifizierungs-Algorithmen bestehen in der Regel aus drei Phasen: In einer Lern- oder Trainingsphase werden Regeln aus Beispielen (beschriftete Daten aus Eingabedaten mit zugeordneten Ausgabedaten), auch Trainingsdaten genannt, abgeleitet. Diese Regeln werden in einer Test- oder Validierungsphase auf andere, ebenfalls beschriftete Daten angewendet, damit geprüft werden kann, wie gut die gelernten Regeln bei anderen Eingabewerten funktionieren.3 Danach können die so trainierten Klassifikatoren in der praktischen Anwendung auf neue, unbeschriftete Daten angewendet werden. Dies ist ein Thema, mit dem sich die Literatur in der Regel nicht mehr beschäftigt.
Im Folgenden sollen drei großen Gruppen der Klassifizierungs-Algorithmen sowie ihre jeweilige Funktion beschrieben werden. Zuvor soll jedoch noch ein wichtiges allgemeines Konzept der Klassifizierung eingeführt werden. Lösungen für Klassifikationsaufgaben haben immer das Risiko der Überanpassung (englisch „Overfitting“), bei der die Entscheidungs-Regeln zu stark auf die Trainingsdaten angepasst wurden und somit bei den Validierungsdaten und damit in der späteren praktischen Anwendung nicht ausreichend gut funktionieren.
We will say that a hypothesis overfits the training examples if some other hypothesis that fits the training examples less well actually performs better over the entire distribution of instances.4
Abb. 1: Zu komplexes Modell Abb. 2: Zu einfaches Modell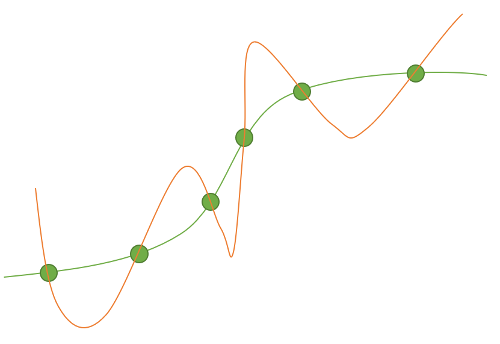
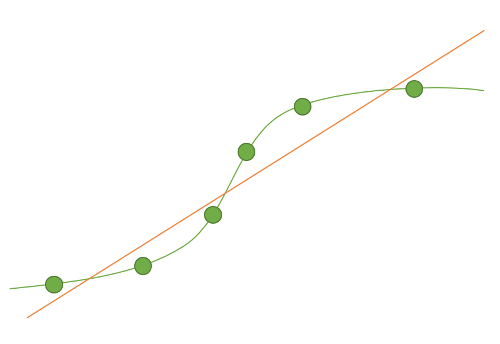
Eine Veranschaulichung des Konflikts aus Überanpassung und zu starker Generalisierung ist in den Abbildungen 1 und 2 dargestellt. Die grüne Kurve beschreibt die tatsächliche Verteilung der Daten in der Realität, die grünen Punkte die zum Training verwendeten Beispiele. Die rote Kurve stellt die gelernte Verteilung der Daten dar, die in Abbildung 1 zwar sehr nah an den Beispieldaten ist, aber nicht der realen Verteilung der Daten entspricht. In Abbildung 2 hingegen ist die gelernte rote Kurve zu einfach, um die tatsächliche Verteilung der Daten ausreichend gut anzunähern.
Entscheidungsbäume
Entscheidungsbäume gehören zu den einfachsten Methoden des maschinellen Lernens und den intuitivsten Verfahren zur Klassifizierung.13 Sie funktionieren, indem sie die Menge möglicher Eingabewerte durch hierarchische Unterteilung so weit eingrenzen, bis eine Zuordnung einer bestimmen Klasse möglich ist.3 Ein einfacher Entscheidungsbaum ist in Abbildung 3 abgebildet. Um ein neues Eingabebeispiel zu klassifizieren, wird dem Baum entsprechend der an Kanten festgelegten Bedingungen gefolgt, bis man an einem Endknoten eine Klasse erhält.4
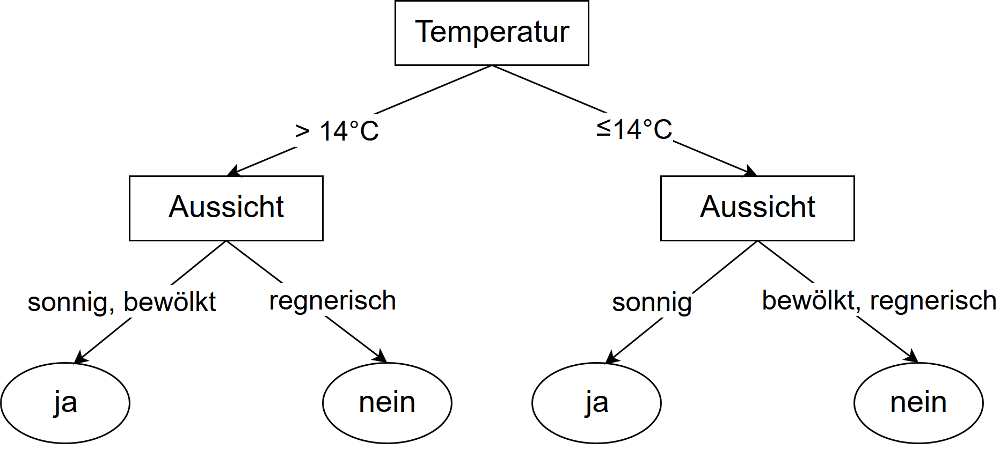
Abb. 3: Ein einfacher Entscheidungsbaum: „Soll ich einen Spaziergang machen?“
Grundsätzlich können die unterschiedlichen Attribute der Eingabedaten in jedem Pfad des Baumes in beliebiger Reihenfolge vorkommen. So könnte in Abbildung 3 auch „Aussicht“ statt „Temperatur“ der Wurzelknoten des Baums sein. Da dies jedoch in exponentiellem Berechnungsaufwand resultieren würde, werden Entscheidungsbäume in einem „top-down“ genannten Verfahren von der Baumwurzel gebildet, sodass für jeden Knoten das Attribut als Entscheidungsvariable verwendet wird, das die „größte Verbesserung der Klassifikationsleistung erbringen würde“.2
Um diese Verbesserung messbar zu machen, wurden verschiedene Entscheidungsgrößen entwickelt, die die Basis unterschiedlicher Typen von Entscheidungsbäumen bilden. Einer der ersten Entscheidungsbäume verwendete beispielsweise die Reduktion der Entropie innerhalb der mittels der neuen Entscheidungsvariable eingeteilten Untergruppen als einen solchen Maßstab. Der weit verbreitete CART-Entscheidungsbaum (CART steht dabei für Classification and Regression Tree) verwendet den Gini-Index als Maßstab für Ungleichverteilung:3
ist dabei die Wahrscheinlichkeit, zufällig den Wert aus dem Wertebereich in der Menge auszuwählen, entsprechend die Wahrscheinlichkeit, ihn zufällig falsch zu klassifizieren – was wahrscheinlicher ist, wenn die Werte eher ungleich verteilt sind. Ein Wert nahe bedeutet eine also gleichmäßige Verteilung der Werte aus dem Wertebereich in der Menge , ein Wert nahe eine Ungleichverteilung. Für die Entwicklung eines Entscheidungsbaums sind jene Mengen besser, deren Werte gleichverteilt sind, wodurch sie besser zu einer Klasse zugeordnet werden können. Der Informationsgewinn , den es bei jeder Aufteilung des Entscheidungsbaums zu maximieren gilt, wird wie folgt definiert:3
ist dabei die Menge der Werte, die es an einem Knoten des Entscheidungsbaums aufzuspalten gilt, das Kriterium, nach dem Teilmengen aus gebildet werden. Ziel ist es, das Kriterium auszuwählen, bei dem maximal ist.3
Entscheidungsbäume neigen jedoch zur Überanpassung, da der Trainingsfehler auf einer bestimmten Menge Trainingsdaten minimiert wird. Die trainierten Bäume werden daher in der Regel mit einer anderen Datenmenge (Validierungsdaten) in einem zweiten Schritt „gestutzt“ (Pruning).2 Bei CART-Entscheidungsbäumen wird ein Verfahren verwendet, das Teilbäume anhand eines Komplexitäts-Nutzen-Verhältnisses bewertet und bei Bedarf durch einzelne Blätter ersetzt.3
Ein Problem von Entscheidungsbäumen ist ihre strukturelle Instabilität. Bereits kleine Veränderungen in den Trainingsdaten können wegen des Top-Down-Ansatzes zu einer vollkommen anderen Reihenfolge der Entscheidungs-Attribute auf den einzelnen Ebenen des Baumes führen. Mit Methoden wie Bagging und Boosting werden daher mehrere Entscheidungsbäume auf unterschiedlichen Teilmengen der Trainingsdaten trainiert. Bei der Anwendung der so trainierten Bäume auf neue zu klassifizierende Daten findet schlussendlich eine (gewichtete) Mehrheitsentscheidung statt:2 Klassifizieren zum Beispiel 90 Bäume die Daten als „Klasse A“ und nur 10 die Daten als „Klasse B“, wird „Klasse A“ als Gesamtentscheidung angenommen. Random Forests sind eine von Leo Breiman entwickelte Umsetzung unter anderem des Bagging-Verfahrens, bei dem Overfitting durch die große Zahl der Bäume vermieden wird.56
Neuronale Netze
Ein künstliches neuronales Netz ist ein Graph aus miteinander verbundenen Einheiten, die ein mathematisches Modell biologischer Neuronen repräsentieren.3 Eine einzelne dieser Einheiten, wie sie in Abbildung 4 dargestellt ist, besteht dabei aus mehreren Eingangssignalen , die multipliziert mit Übertragungsgewichten zu einem Potential aufsummiert werden. Dieses wird mit einer Aktivierungsfunktion in ein Ausgabesignal, die Erregung , umgewandelt.21.
![Abb. 4: Ein künstliches Neuron. Abbildung aus [3]](/posts/2018/von-baeumen-netzen-und-maschinen/neuron.png)
Abb. 4: Ein künstliches Neuron. Abbildung aus [3]
Durch Verknüpfung der künstlichen Neuronen können so beliebig komplexe Strukturen konstruiert werden. Durch die Definition einer einfachen Aktivierungsfunktion
und geschickte Wahl der Gewichte sowie des Schwellwerts kann bereits mit einem einzelnen Neuron das logische UND beziehungsweise ODER dargestellt werden.5 Fügt man vor die Ebene des Ausgabe-Neurons eine weitere Ebene mit sogenannten „versteckten Neuronen“ (einen hidden layer), so lassen sich bereits beliebige Boole’sche Ausdrücke darstellen und beliebige Funktionen annähern.7
![Abb. 5: Ein Multi Layer Perceptron mit sigmoidaler Aktivierungsfunktion. Abbildung aus [4]](/posts/2018/von-baeumen-netzen-und-maschinen/netz.png)
Abb. 5: Ein Multi Layer Perceptron mit sigmoidaler Aktivierungsfunktion. Abbildung aus [4]
Die Einführung von Ebenen versteckter Neuronen, die jeweils nur vollständig mit der darauffolgenden Schicht verbunden sind (feedforward), wie es in Abbildung 5 dargestellt ist, ermöglicht die Durchführung selbst komplexer Klassifikationsaufgaben. Man spricht von „multi-layer feedforward networks“ oder Multi Layer Perceptrons (MLPs), sowie Deep Learning.3
Zur Bestimmung der Gewichte wurden verschiedene Lernregeln entwickelt. Effizientes Training von MLPs wurde erst 1986 durch die Entwicklung von Back-Propagation möglich,83 das auf Gradientabstieg (gradient descent) basiert und bereits 1974 durch Paul Werbos vorgeschlagen wurde.79 Ziel ist die Minimierung des Fehlers an den Neuronen des Output Layers, wobei die entsprechenden Trainingswerte sind. wird wie folgt definiert:24
Dieser Fehler ist nun abhängig von der Wahl der Gewichte . Jedes einzelne Gewicht wird dann iterativ gemäß der Ableitung des Fehlers nach dem entsprechenden Gewicht angepasst:34
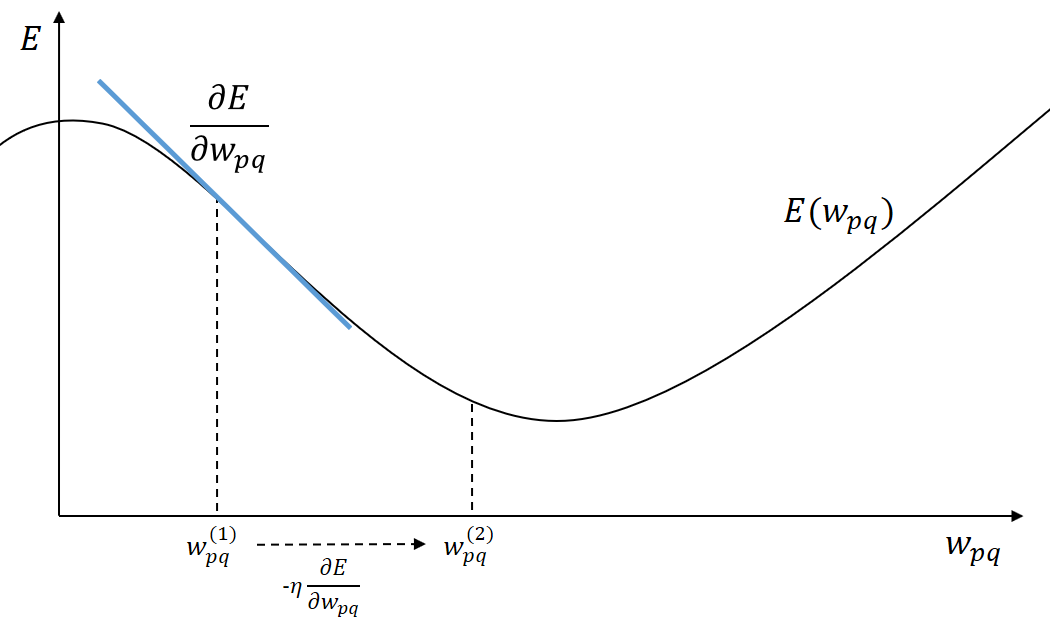
Abb. 6: Veranschaulichung des Gradientabstiegs beim Back-Propagation-Algorithmus
In der ersten Gleichung ist die Veränderung angegeben, die in der zweiten Gleichung iterativ auf das Gewicht angewendet wird. ist dabei der Nabla-Operator, der dazu verwendet wird, den Gradienten anzugeben. ist dabei ein beim Training zu wählender Faktor, der die Lerngeschwindigkeit bestimmt. In Abbildung 6 ist ein Iterationsschritt für ein Gewicht visualisiert. Für Gewichte des Output Layers lässt sich die partielle Ableitung trivial bestimmen. Es gilt2
Um die partiellen Ableitungen für die Gewichte eines Hidden Layers zu bestimmen, muss in der Gleichung für das Eingangssignal des Output Layers die Formel zu dessen Berechnung aus dem Hidden Layer eingesetzt werden, wobei die Eingangssignale des Hidden Layers sind. Durch Umformen erhält man2
Wie leicht ersichtlich ist, unterscheiden sich die Terme zur Berechnung der partiellen Ableitung des Fehlers für Output Layer und Hidden Layer nur in bzw. . enthält insbesondere jeweils die des nachfolgenden Layers, sodass alle und hierarchisch vom Output Layer bis zum vordersten Hidden Layer berechnet werden können (wodurch sich der Name „Back-Propagation“ ergibt). Dies funktioniert theoretisch mit beliebig vielen Hidden Layers.
Wichtige Voraussetzung für Back-Propagation ist Differenzierbarkeit der Aktivierungsfunktion , wobei trotzdem eine „schrittartige“ Struktur wie im oben vorgestellten naiven Ansatz angestrebt werden soll. In der Praxis (und zum Beispiel in Abbildung 5) wird häufig eine Sigmoidfunktion wie etwa die logistische Funktion verwendet:321
Bei Back-Propagation muss beachtet werden, dass insbesondere ein ungeschickt gewähltes dazu führen kann, dass das Training nur in einem (unter Umständen sehr schlechten) lokalen Minimum statt eines gewünschten globalen resultiert. Eine Erweiterung des Back-Propagation-Algorithmus führt daher den Momentum-Faktor ein, der beim Gradientabstieg auch die Veränderung der Gewichte bei der letzten Iteration einbezieht. Außerdem beeinflussen die initialen Werte der Gewichte das Trainings-Ergebnis, weswegen sie häufig gemäß der Standardnormalverteilung zufällig belegt werden. Zudem werden die numerischen Eingabedaten häufig normalisiert, sodass sie im Wertebereich von liegen.3
Für kategorische Variablen hat sich das sogenannte „One-Hot“-Encoding etabliert, bei dem pro Eingangssignal eine Klasse existiert. Ist eine Klasse aktiv, ist der Wert des entsprechenden Signals ; der aller anderen ist . Auch im Output Layer kann diese Kodierung verwendet werden. So wird jene Klasse als ausgewählt angenommen, deren Neuron den größten Ausgabewert hat.3 Da diese Werte in der Praxis jedoch nie eindeutig und sein werden, können sie auch als Abschätzung der Wahrscheinlichkeit der korrekten Klassifizierung verwendet werden.3
Ein wichtiger Teil beim Training von neuronalen Netzen ist die Vermeidung von Überanpassung durch zu häufige Iteration des Back-Propagation-Algorithmus. Eine häufig genutzte Methode ist hierbei die regelmäßige Abschätzung des Klassifizierungs-Fehlers während des Trainings mit einem separaten Satz an Validierungsdaten, um einen geeigneten Zeitpunkt zum Abbruch des Trainings zu finden.321 Weitere Herausforderungen sind die Wahl einer geeigneten Netzstruktur (Anzahl und Größe der Hidden Layer) sowie der Umgang mit zu kleinen Mengen an Trainingsdaten bei zu vielen Parametern, was in einer unverhältnismäßig großen Zahl an anzupassenden Gewichten resultiert.3
Neuronale Netze sind ein sehr mächtiges Werkzeug, das sich in vielen Bereichen einsetzen lässt. So lassen sich MLPs auch für Regressionsprobleme verwenden und mit dem Hinzufügen von „Convolutions“ genannten Schichten lassen sich unter anderem Bilderkennungsprobleme effizient lösen.7 Die flexible Verschaltung von Neuronen ermöglicht darüber hinaus Netzwerke, bei denen sich Verbindungen nicht nur vorwärts, sondern auch wieder zurück zu Neuronen in vorigen Schichten erstrecken. Solche rekurrenten neuronalen Netze ermöglichen die Simulation von Gedächtnis-Prozessen, was sich zum Beispiel zur Vervollständigung von Mustern nutzen lässt.71 Darüber hinaus können neuronale Netze auch im Bereich des unüberwachten Lernens und des Verstärkungslernens eingesetzt werden. Die vielfältige Nutzung in Forschung und Praxis ist starkes Indiz für die Vorteile neuronaler Netze.10
Nachteil neuronaler Netze ist insbesondere die schwere Verständlichkeit der generierten Modelle4 und die komplexe Anpassung der Struktur und Parameter des Netzes13 sowie die Dauer des Trainings.4
Support Vector Machines
Support Vector Machines (deutsch vereinzelt auch „Stützvektormethode“2) sind der neueste und zurzeit „populärste Ansatz für überwachtes Lernen“.1 Sie wurden in den 1990ern von Vladimir Vapnik et al. (Dieser Artikel verwendet die englische Transkription des russischen Namens) mit der Motivation entwickelt, die Überanpassung bestehender Modelle wie Entscheidungsbäume und neuronale Netze zu vermeiden.311
Die Idee hinter Support Vector Machines ist es, Klassifizierungsaufgaben nicht durch „Lernen“ einer Funktion (wie etwa bei neuronalen Netzen), sondern durch „Konstruktion“ einer idealen Trennlinie zu lösen. Die Trainingsdaten in der Form
wie sie in Abbildung 7 beispielhaft für dargestellt sind, und sollen durch eine Hyperebene , definiert durch eine lineare Funktion mit einem Vektor an Gewichten , so voneinander getrennt werden, dass der Mindestabstand der Punkte von maximal ist. Man spricht in diesem Fall vom Maximum Margin Classifier.31

Abb. 7: Zwei Klassen von Punkten, die durch eine Hyperebene getrennt werden
Der Abstand eines Punktes von lässt sich definieren als
wobei ein Abstandsmaß wie zum Beispiel die euklidische Norm ist.2 drückt aus, dass der Vektor transponiert wird, sodass das Produkt ein Skalar ist. Für Punkte auf der richtigen Seite von gilt3
Die Maximierung des Abstandes lässt sich also als das folgende Optimierungsproblem formulieren:
Das Problem an dieser Formulierung ist jedoch, dass durch Skalierung der Hyperebene unendlich viele optimale Lösungen existieren. Daher wird diese normiert, indem gesetzt wird. Wird maximiert, muss also minimiert werden. Durch Multiplikation der Nebenbedingungen mit ergibt sich somit
In der Literatur wird der zu minimierende Term häufig in einen äquivalenten Ausdruck umformuliert, was die spätere Berechnung vereinfacht, da zum Beispiel der Wurzelterm der euklidischen Norm entfällt.311
Dieses Gleichungssystem kann mit Hilfe von Lagrange-Relaxion gelöst werden,311 auf die hier jedoch nicht näher eingegangen werden soll. Die Lösung besteht aus dem Parameter sowie einem Vektor , aus dem sich unter Zunahme der verwendeten Trainingsdatensätze der Gewichtsvektor bestimmen lässt.3
In Abbildung 7 ist leicht erkennbar, dass im Gegensatz zu den bisher besprochenen Verfahren nicht alle Trainingsdaten für die exakte Position der Hyperebene verantwortlich sind, sondern nur diejenigen, die nah an der trennenden Hyperebene liegen. Diese Punkte werden Support Vectors genannt. Nur für einen Support Vector ist der Wert ungleich .
Dieser Ansatz der Support Vector Machines führt zu einer bedeutenden Einschränkung für die Daten: Sie müssen durch eine Hyperebene trennbar, „linear separabel“12 sein. Dies muss jedoch aus zwei Gründen nicht immer der Fall sein. Diesen kann mit unterschiedlichen Maßnahmen begegnet werden:
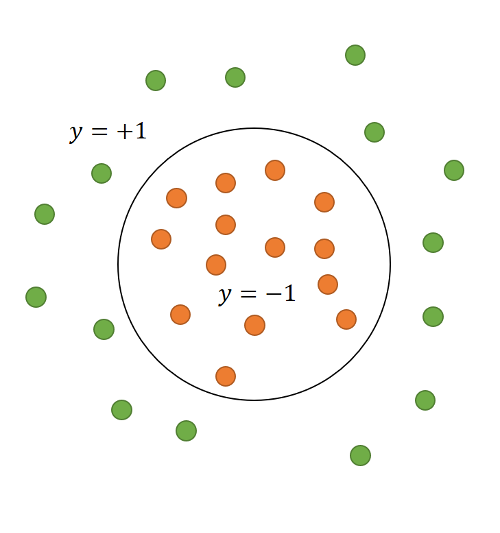
Abb. 8: Fehlerhafte/verrauschte Trainingsdaten Abb. 9: Nicht linear trennbare/separable Daten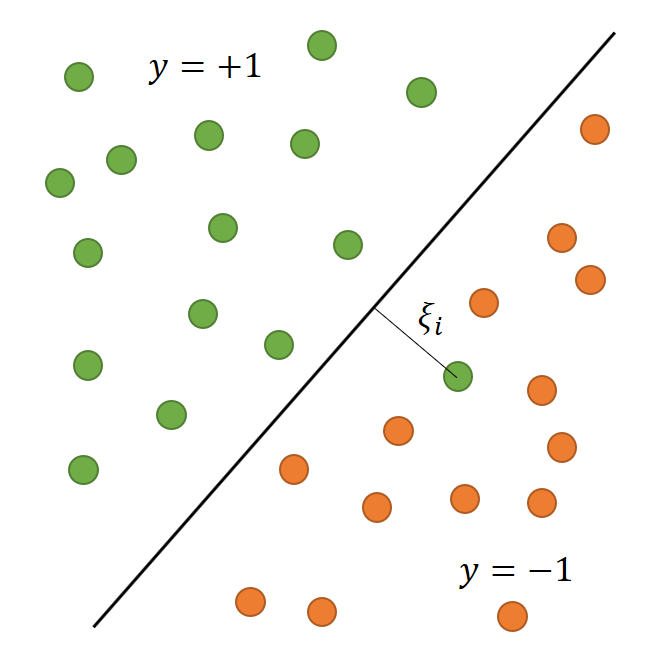
Soft-Margin
Wie in Abbildung 8 dargestellt, ist es möglich, dass in den Trainingsdaten Fehler vorliegen, zum Beispiel weil sie verrauscht sind. Damit die Berechnung der Hyperebene nicht scheitert, wird eine Schlupfvariable definiert, die fehlerhafte Daten nicht verbietet, aber bestraft.3 Man spricht hierbei von Soft-Margin-Klassifikatoren.1 Das Optimierungsproblem kann weiterhin analog mittels Lagrange-Relaxion gelöst werden.
Kernel-Trick
Wie in Abbildung 9 dargestellt, ist es möglich, dass die Daten ihrer Struktur nach schlicht nicht linear separierbar sind. Hier wird ein Kernel-Trick genanntes Verfahren angewendet: Die Datenpunkte werden mit Hilfe einer nicht-linearen Funktion in einen (in der Regel) höherdimensionalen Raum abgebildet, in welchem sie linear trennbar sind (wie zum Beispiel in Abbildung 10 mit dem Kernel ). Durch Rücktransformation der in diesem höherdimensionalen Raum gelernten Hyperebene können sie beliebigen nicht-linearen Entscheidungs-Grenzen entsprechen.23 Diese Transformation lässt sich bei der Lösung des Optimierungsproblems in Form einer sogenannten Kernel-Funktion einsetzen, sodass zeitaufwendige Berechnungsschritte vermieden und sogar Räume mit unendlich vielen Dimensionen verwendet werden können.31
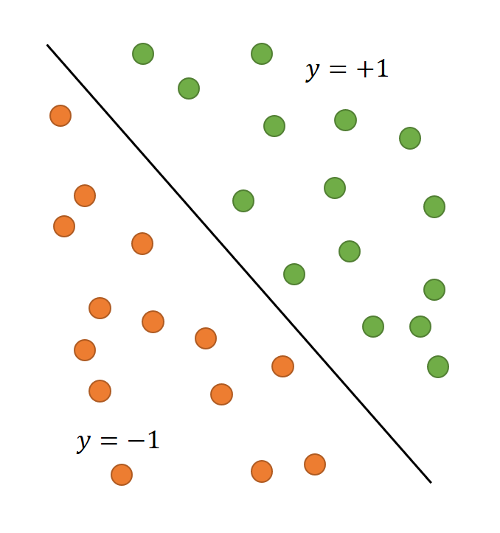
Abb. 10: Mit einem Kernel transformierte Daten
Support Vector Machines, wie sie bisher beschrieben wurden, erlauben nur die Unterscheidung zweier unterschiedlicher Klassen. Es existieren jedoch verschiedene Verfahren, mit denen auch Klassifizierungsaufgaben mit mehreren Ziel-Klassen durch die Verknüpfung mehrerer Support Vector Machines gelöst werden können.3 Auf eine nähere Beschreibung dieser Verfahren wird hier jedoch verzichtet.
Vorteil von Support Vector Machines ist ihre gute Generalisierung31 sowie ihre Anwendbarkeit bei einer sehr großen Zahl an Merkmalen.2 Nachteil ist die Notwendigkeit der manuellen Auswahl eines geeigneten Kernels bei nicht linear trennbaren Daten.
Fazit
Ich hoffe, ich habe Sie, werte Leser, mit den mathematischen Grundlagen der einzelnen Verfahren nicht zu sehr abgeschreckt und konnte Ihnen stattdessen die Grundprinzipien, Vorteile und Nachteile von drei sehr wichtigen Methoden innerhalb der künstlichen Intelligenz in fundierter Form nahebringen.
Ich möchte nicht verschweigen, dass es noch einige weitere Verfahren innerhalb des maschinellen Lernens gibt – K-Nearest Neighbor und Naive Bayes zum Beispiel. Den mathematisch interessierten Lesern kann ich eine mehrwöchige, kostenlose Online-Schulung von Andrew Ng, der unter anderem das Projekt Google Brain gegründet hat, nur nahelegen.13 Hier werden zwar auch bei weitem nicht alle Themen besprochen, dafür wird jedoch sehr viel Wert auf die Herleitung und die Grundlagen gelegt.
Zum Abschluss kann ich Ihnen nur empfehlen, einmal durch eines der hier angesprochenen Übersichtsbücher durchzublättern (so es denn in der örtlichen Bibliothek verfügbar ist), um zu sehen, wie umfangreich dieses Thema, das unseren Alltag immer tiefer durchdringt, doch ist.
Stuart Russel; Peter Norvig. Künstliche Intelligenz: Ein moderner Ansatz. 3., aktualisierte Auflage. München: Pearson, 2012. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Günther Görz, Hrsg. Handbuch der Künstlichen Intelligenz. 5., überarbeitete und aktualisierte Auflage. München: Oldenbourg, 2014. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Charu C. Aggarwal, Hrsg. Data Classification: Algorithms and Applications. Boca Raton: CRC Press, 2015. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Tom M. Mitchell. Machine Learning. New York, NY, USA: McGraw-Hill, 1997. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Leo Breiman. „Random Forests“. In: Machine Learning 45.1 (2001), S. 5–32. ↩︎ ↩︎
Adele Cutler; D. Richard Cutler; John R. Stevens. „Random Forests“. In: Ensemble Machine Learning: Methods and Applications. Hrsg. von Cha Zhang und Yunqian Ma. Boston, MA: Springer US, 2012, S. 157–175. DOI: 978-1-4419-9326-7_5. ↩︎
Haohan Wang; Bhiksha Raj. „On the Origin of Deep Learning“. In: CoRR abs/1702.07800 (2017). Link (besucht am 27.03.2017). ↩︎ ↩︎ ↩︎ ↩︎
Vladimir N. Vapnik. The nature of statistical learning theory. 2. ed. Statistics for engineering and information science. New York: Springer, 2000. ↩︎
Paul Werbos. „Beyond regression: New tools for prediction and analysis in the behavioral sciences“ Diss. Cambridge, Massachusetts: Harvard University, Aug. 1974. ↩︎
Terry T. Um Awesome – Most Cited Deep Learning Papers. 2017. Link (besucht am 30.03.2017). ↩︎
Bernhard E. Boser; Isabelle M. Guyon; Vladimir N. Vapnik. „A Training Algorithm for Optimal Margin Classifiers“. In: Proceedings of the Fifth Annual Workshop on Computational Learning Theory. COLT ’92. Pittsburgh, Pennsylvania, USA: ACM, 1992, S. 144–152. DOI: 10.1145/130385.130401. ↩︎ ↩︎ ↩︎
Wolfgang Ertel. Grundkurs Künstliche Intelligenz: Eine praxisorientierte Einführung. 1. Auflage. Wiesbaden: Vieweg, 2008. ↩︎
Andrew Ng Machine Learning. Online-Schulung der Stanford University auf Coursea. Link (besucht am 28.06.2017). ↩︎